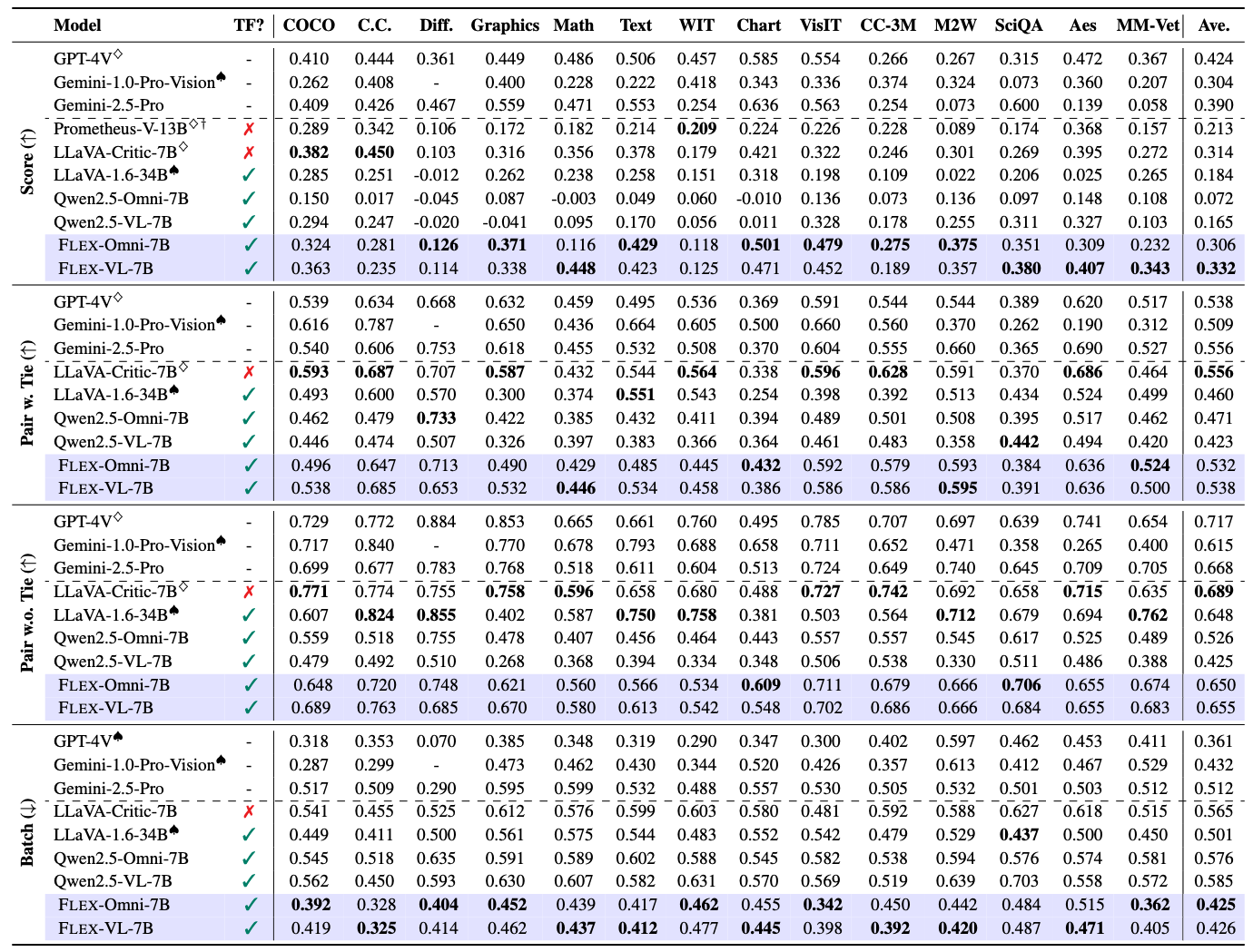
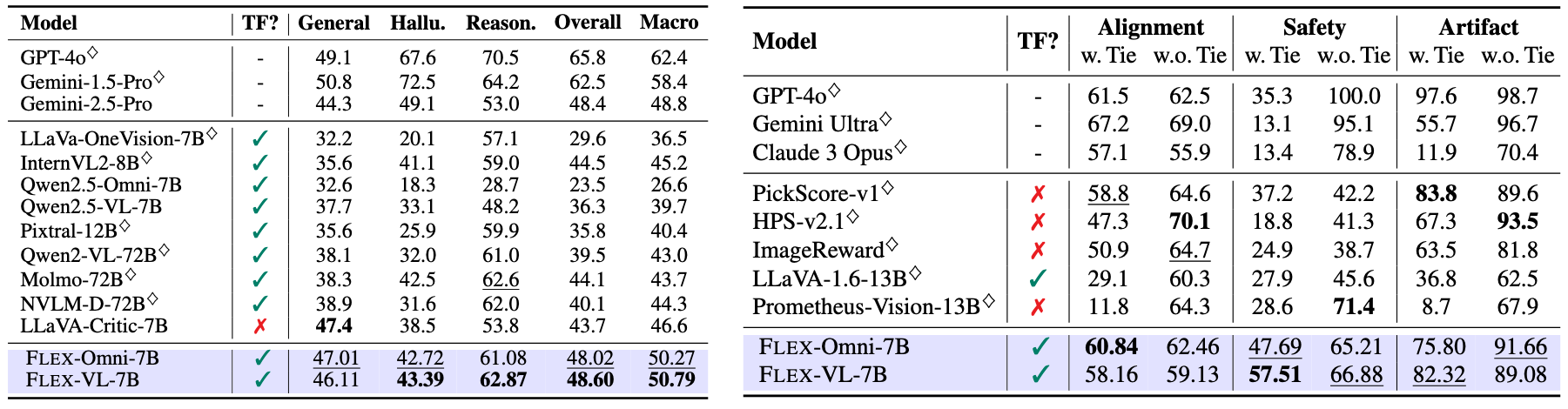
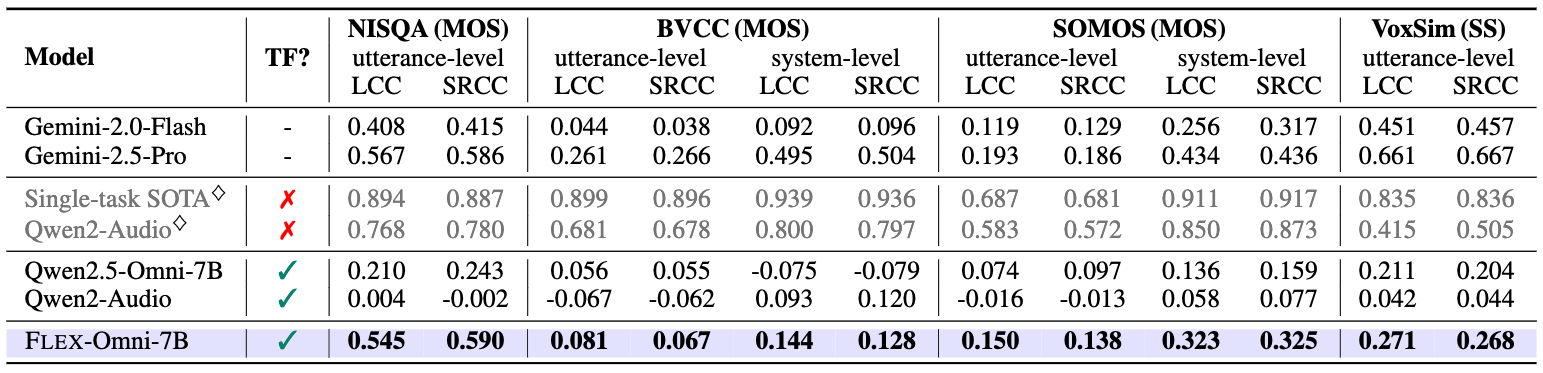
Human-generated reward signals are critical for aligning generative models with human preferences, guiding both training and inference-time evaluations. While large language models (LLMs) employed as proxy evaluators, i.e., LLM-as-a-Judge, significantly reduce the costs associated with manual annotations, they typically require extensive modality-specific training data and fail to generalize well across diverse multimodal tasks. In this paper, we propose Flex-Judge, a reasoning-guided multimodal judge model that leverages minimal textual reasoning data to robustly generalize across multiple modalities and evaluation formats. Our core intuition is that structured textual reasoning explanations inherently encode generalizable decision-making patterns, enabling an effective transfer to multimodal judgments, e.g., with images or videos. Empirical results demonstrate that Flex-Judge, despite being trained on significantly fewer text data, achieves competitive or superior performance compared to state-of-the-art commercial APIs and extensively trained multimodal evaluators. Notably, Flex-Judge presents broad impact in modalities like molecule, where comprehensive evaluation benchmarks are scarce, underscoring its practical value in resource-constrained domains. Our framework highlights reasoning-based text supervision as a powerful, cost-effective alternative to traditional annotation-intensive approaches, substantially advancing scalable multimodal model-as-a-judge.
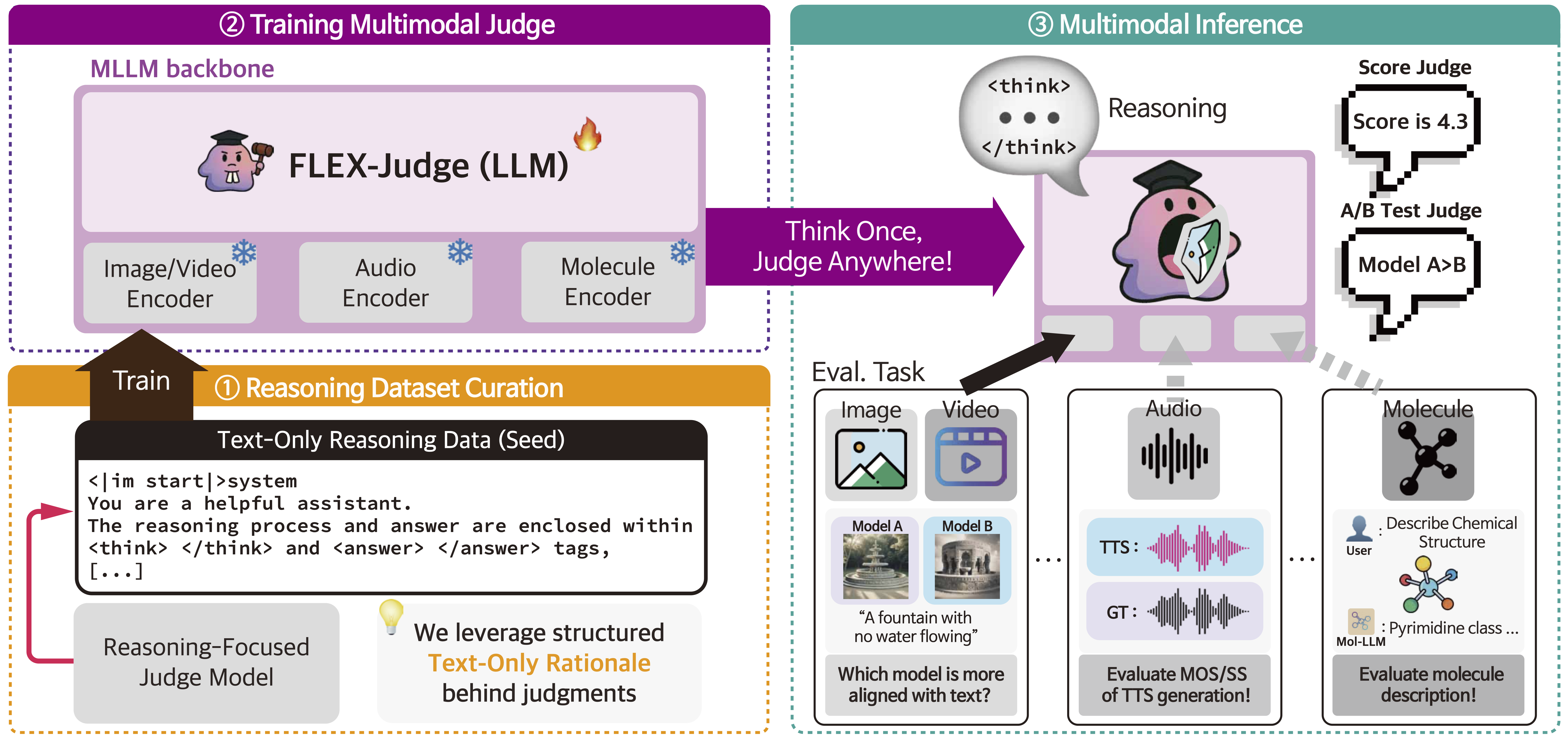
 Judge
Judge